03. pima indians 데이터로 의사결정나무 만들기 (python)
사용한 패키지.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
-> data 폴더에 저장한 diabates csv 파일을 사용했다. 파일 출처는 캐글. pima indians 로 검색하면 나온다. 768행짜리.
df.head()-> 위쪽 행들을 확인해서 맞게 불러왔는지 확인해보자.
split_count = int(df.shape[0] * 0.8)
split_count-> 데이터를 8:2 로 나누는 과정. 학습데이터셋인 train과 테스트데이터셋인 test를 8:2 비율로 나눠 줬다.
train = df[:split_count].copy()
train.shape-> out이 (614, 9)로 나오는데 열이 614, 행이 9개라는 뜻.
df-> df 확인해보면?
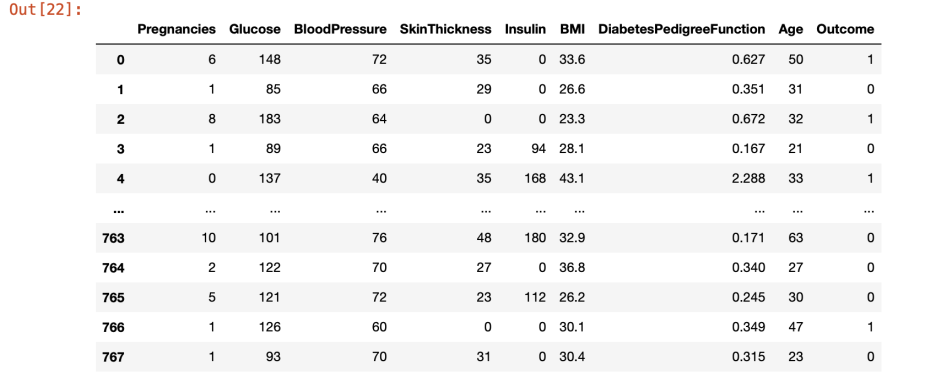
사진 설명을 입력하세요.
이런식으로 767까지 확인됐다.
test = df[split_count:].copy()
test-> train 데이터도 나눠줬으니 test 데이터도 나눠줘야 한다. 그래서 나눠줬다.
feature_names = train.columns[:-1].tolist()
feature_names-> 하지만 train 데이터에서는 output 행이 빠져야 한다. 시험을 보는데 답이 있으면 안되니까... (output이 답이다. 당뇨가 걸렸는지 걸리지 않았는지 이 행에 저장된다.) train.colums[:-1]이 output을 제외하는 코드다. output은 행의 마지막에 있었기 때문에 -1을 빼주는거다.
label_name = train.columns[-1]
label_name-> label_name 변수에 예측할 컬럼의 이름을 담기. (outcome)
X_train = train[feature_names]
print(X_train.shape)
X_train.head()-> 학습 세트를 만들어 줬다. 시험의 기출문제로 생각하면 된다.
X_train은 기출문제. y_train은 정답.
y_train = train[label_name]
print(y_train.shape)
y_train.head()-> 정답 값 만들기.
X_test = test[feature_names]
print(X_test.shape)
X_test.head()-> 예측에 사용할 데이터세트 만들었다. 실전 문제.
y_test = test[label_name]
print(y_test.shape)
y_test.head()-> 예측의 정답값. 실전 시험 문제의 정답.
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model-> 머신러닝 알고리즘 가져오기
model.fit(X_train, y_train)-> 학습(훈련)한다.
시험을 볼 때 기출문제(X_train)와 정답(y_train)을 보고 공부하는 과정과 유사함.
y_predict = model.predict(X_test)
y_predict[:5]-> 예측한다.
실전 시험문제(X_train)라고 보면 됨. 우리가 정답을 직접 예측함.
from sklearn.tree import plot_tree
plt.figure(figsize = (20,20))
tree = plot_tree(model,
feature_names = feature_names,
filled = True,
fontsize = 10)-> 트리 알고리즘 분석하기.
의사결정나무 시각화.
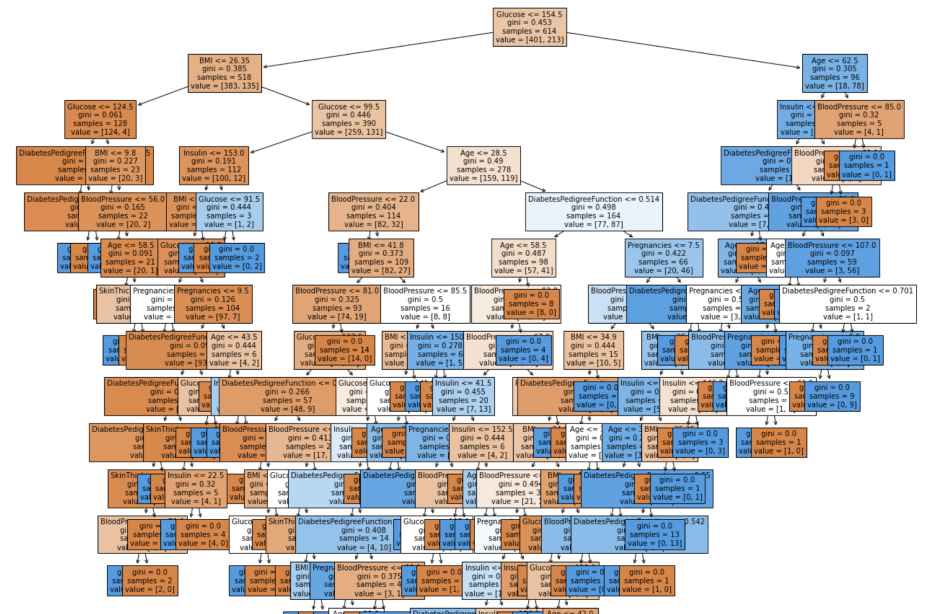
사진 설명을 입력하세요.
model.feature_importances_-> 피처의 중요도를 추출하기.
sns.barplot(x=model.feature_importances_, y=feature_names)-> 피처의 중요도 시각화하기
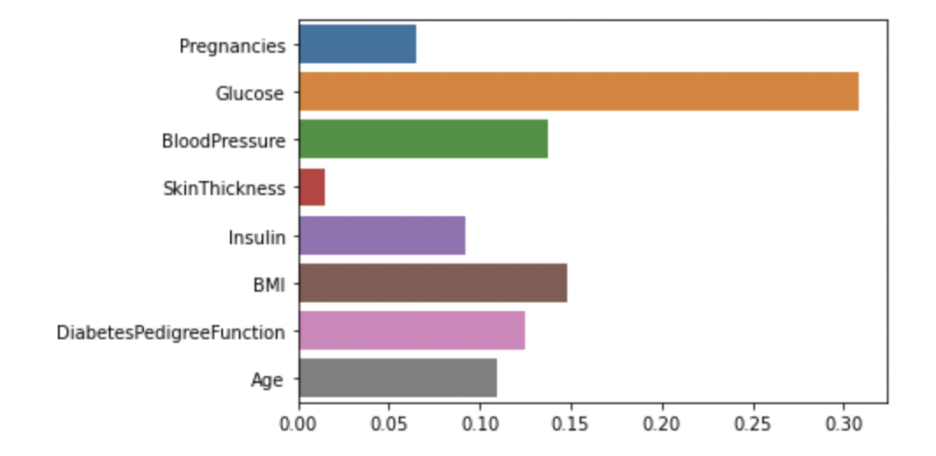
사진 설명을 입력하세요.
이 시각화로 glucose이 당뇨에서 가장 중요도가 높다고 판단할 수 있게됨. 하지만 통상 알고 있는 당뇨병의 주요 발병 원인인 insulin의 중요도가 낮은 이유가 납득되지 않음. 후에 feature engineering으로 정확도를 높여야 함. (이 페이지에서는 하지 않을거임)
abs(y_test - y_predict).sum() / len(y_test)
#이 모델은 약 71퍼센트의 정확도를 가지고 있음.
diff_count = abs(y_test - y_predict).sum()
diff_count-> 정확도(accuracy) 측정하기
이 모델의 성능은 어느 정도인가?
실제값 - 예측값을 빼주면 같은 값은 0으로 나오게 됨.
out이 45로 나옴. 45개가 틀렸다는 뜻.
(len(y_test) - diff_count) / len(y_test) * 100
#70점-> 예측의 정확도 구하기. 100점 만점에 몇 점 맞았을까? out이 70.77922077922078로 나옴. 약 70점이라는 뜻.
하지만 이 값은 조금씩 달라진다. 의사결정나무는 랜덤으로 값을 뽑아내기 때문.
이렇게 직접 구할 수 있지만 미리 구현된 알고리즘을 가져와 사용해 볼 수 도 있음.
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict) * 100-> sklean.matrics로 자동으로 돌린 값. 70.77922077922078. 동일한 값이 나옴.
model.score(X_test, y_test) * 100-> model의 score로 점수를 계산하기. 70.77922077922078. 동일한 값.